1️⃣ 윈도우 함수
∙ 윈도우 함수는 행과 행 간의 관계를 정의하기 위해서 제공되는 함수이다.
∙ 윈도우 함수를 사용해서 순위, 합계, 평균, 행 위치 등을 조작할 수 있다.

| 구조 | 설명 |
| ARGUMENT(인수) | 윈도우 함수에 따라서 0~N개의 인수를 설정한다. |
| PARTITION BY | 전체 집합을 기준에 의해 소그룹으로 나눈다. |
| ORDER BY | 어떤 항목에 대해서 정렬한다. |
| WINDOWING |
- 행 기준의 범위를 정한다. - ROWS는 물리적 결과의 행 수이고, RANGE는 논리적인 값에 의한 범위이다. |
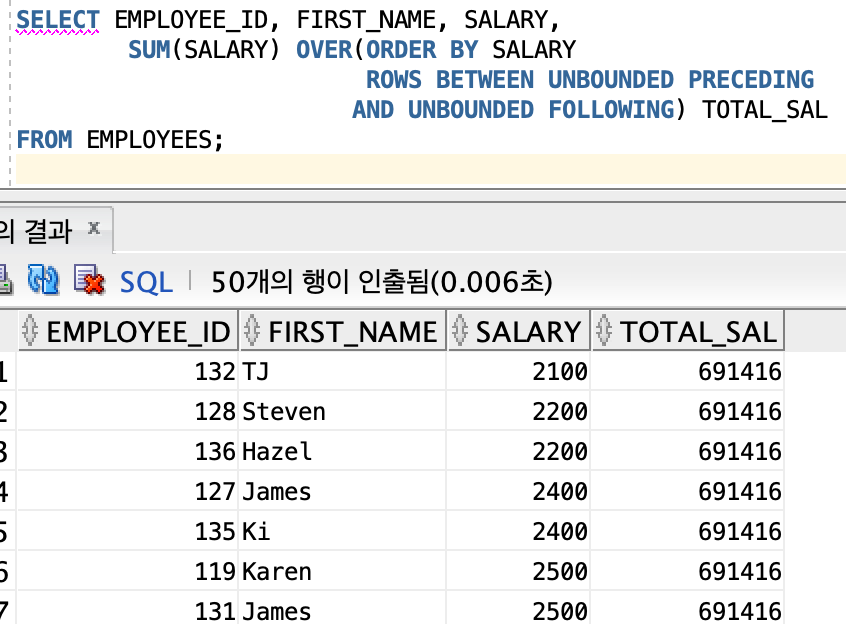
∙ UNBOUNDED PRECEDING은 처음 행을 의미하며, UNBOUNDED FOLLOWING은 마지막 행을 의미한다.
그러므로 TOTAL_SAL에 처음부터 마지막까지의 합계(SUM(SAL))를 계산한 것이다.

∙ 위 SQL은 처음부터 CURRENT ROW까지의 합계를 계산한다. 결과적으로 누적합계가 된다.
∙ 첫 번째 행의 SAL은 2100이고 두 번째 행의 SAL은 2200이다. 그러므로 두 번째 행의 TOTAL_SAL은 4300이 된다.
∙ CURRENT ROW는 데이터가 인출된 현재 행을 의미한다.
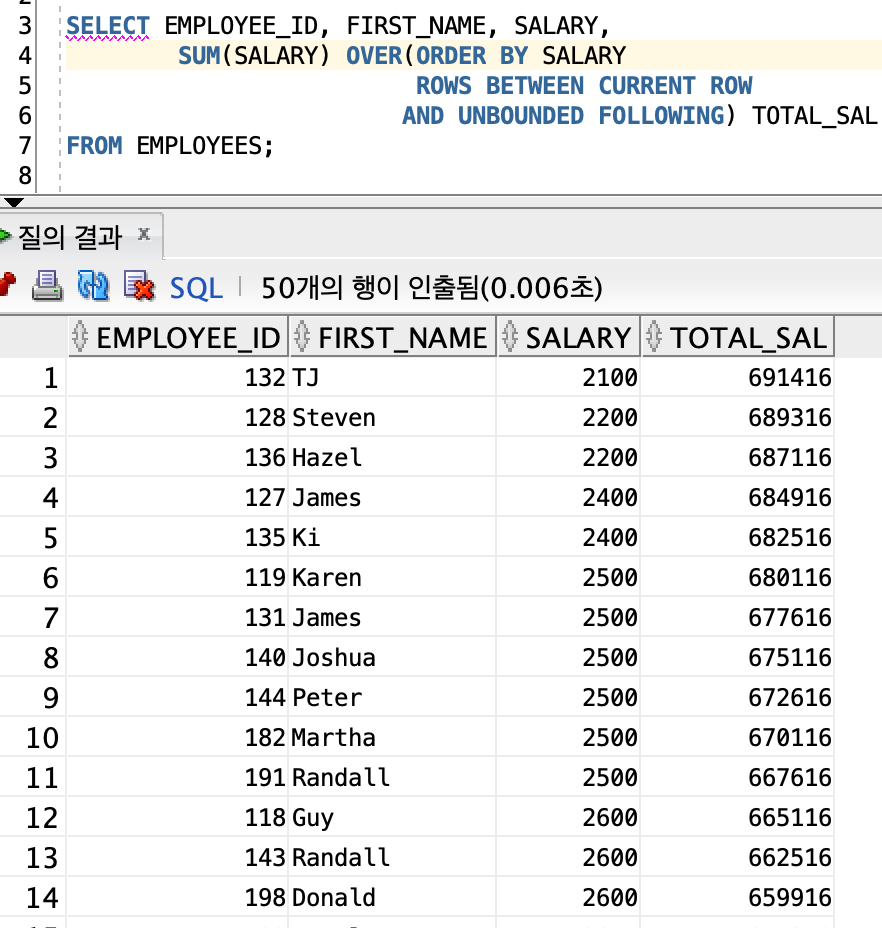
∙ 위 SQL문은 현재 행(CURRENT ROW)부터 마지막 행(UNBOUNDED FOLLOWING)까지의 합계를 계산한다.
∙ 첫 번째 행의 SAL이 2100이므로 2100부터 끝까지의 합계를 TOTAL_SAL에 계싼한다. 결과적으로 전체합계가 된다.
∙ 그 다음 TOTAL_SAL은 2200부터 마지막까지이므로 첫번째 row의 SALARY 2100을 제외된 합계가 된다.
2️⃣ 순위 함수(RANK Function)
∙ 윈도우 함수는 특정 항목과 파티션에 대해서 순위를 계산할 수 있는 함수를 제공한다.
∙ 순위 함수는 RANK, DENSE_RANK, ROW_NUMBER 함수가 있다.
| 순위함수 | 설명 |
| RANK |
- 특정항목 및 파티션에 대해서 순위를 계산한다. - 동일한 순위는 동일한 값이 부여된다. |
| DENSE_RANK | - 동일한 순위를 하나의 건수로 계산한다. |
| ROW_NUMBER | - 동일한 순위에 대해서 고유의 순위를 부여한다. |
- RANK

∙ RANK 함수는 순위를 계산하며, 동일한 순위에는 같은 순위가 부여된다.
∙ RANK 함수는 순위를 계산하며, 동일한 순위에는 같은 순위가 부여된다.
∙ RANK() OVER(ORDER BY SALARY DESC)는 SALARY로 등수를 계산하고 내림차순으로 조회하게 한다.
∙ RANK() OVER(PARTITION BY EMPLOYEE_ID ORDER BY SALARY DESC)는 JOB으로 파티션을 만들고 EMPLOYEE_ID별 순위를 조회하게 한다.
- DENSE_RANK
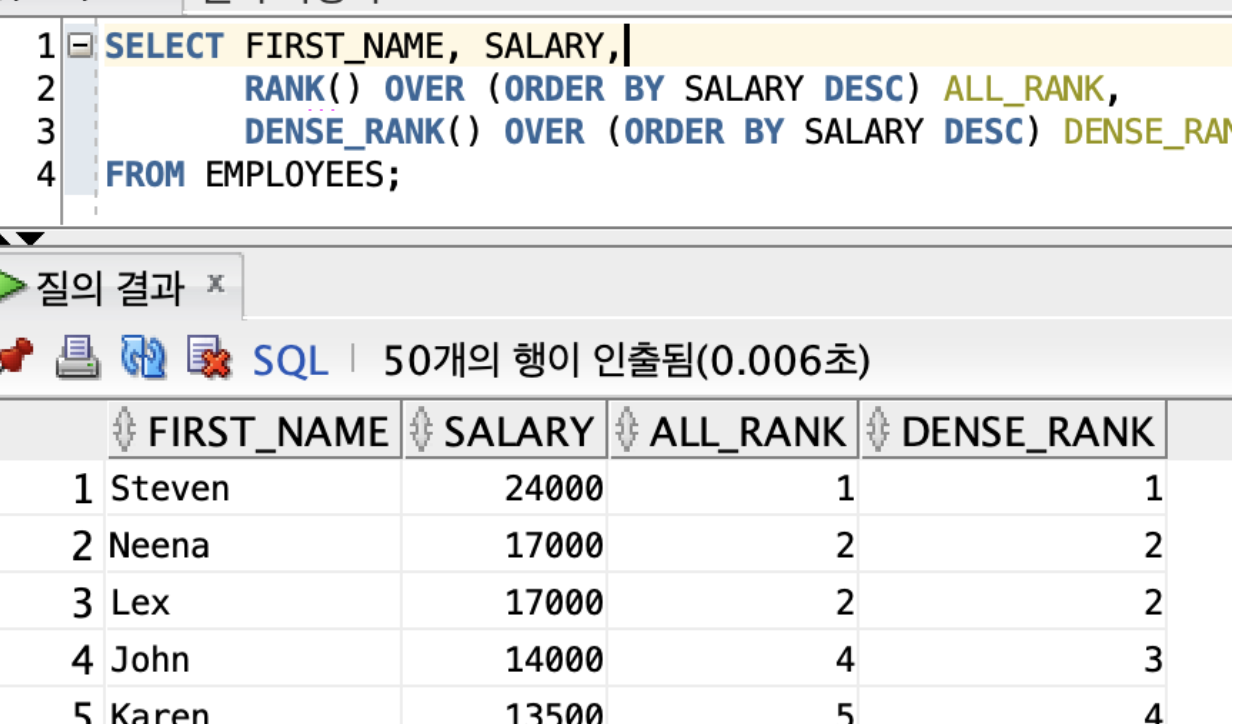
∙ DENSE_RANK는 동일한 순위를 하나의 건수로 인식해서 조회한다. ex) 1위, 2위(2명) -> 4위
- ROW_NUMBER
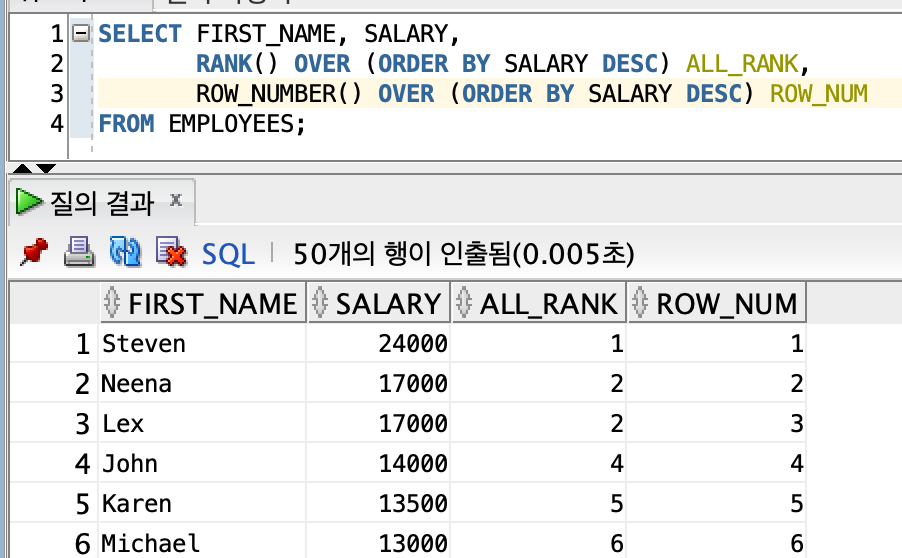
∙ ROW_NUMBER 함수는 동일한 순위에 대해서 고유의 순위를 부여한다.
3️⃣ 집계함수 (RANK Function)
∙ 윈도우 함수를 제공한다.
| 집계함수 | 설명 |
| SUM | 파티션 별로 합계를 계산한다. |
| AVG | 파티션 별로 평균을 계산한다. |
| COUNT | 파티션 별로 행 수를 계산한다. |
| MAX와 MIN | 파티션 별로 최대값과 최소값을 계산한다. |
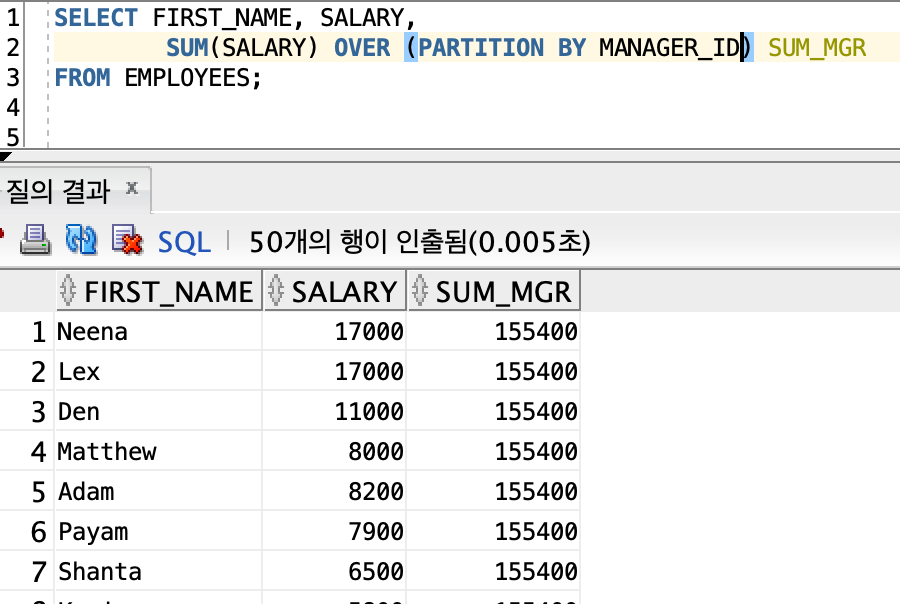
4️⃣ 행 순서 관련 함수
∙ 행 순서 관련 함수는 상위 행의 값을 하위에 출력하거나 하위 행의 값을 상위 행에 출력할 수 있다.
∙ 특정 위치의 행을 출력할 수 있다.
| 행순서 | 설명 |
| FIRST_VALUE |
- 파티션에서 가장 처음에 나오는 값을 구한다. - MIN 함수를 사용해서 같은 결과를 구할 수 있다. |
| LAST_VALUE |
- 파티션에서 가장 나중에 나오는 값을 구한다. - MAX 함수를 사용해서 같은 결과를 구할 수 있다. |
| LAG | 이전 행을 가지고 온다. |
| LEAD |
- 윈도우에서 특정 위치의 행을 가지고 온다. - 기본값은 1이다. |
- FIRST_VALUE

∙ FIRST_VALUE 함수는 파티션에서 조회된 행 중에서 첫 번째 행의 값을 가지고 온다.
∙ SALARY 내림차순으로 조회했기 때문에 부서 내에 가장 급여가 많은 사원이 된다.
- LAST_VALUE

∙ LAST_VALUE 함수는 파티션에서 마지막 행을 가지고 온다. 그래서 FIRST_VALUE와 다르게 부서에서 가장 낮은 급여를 받는 사람이 출력된다.
∙ BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING의 의미는 현재 행에서 마지막 행까지의 파티션을 의미한다.
- Lag
∙ LAG 함수는 이전 값을 가지고 오는 것이다. 예를 들어 PRE_SAL의 값의 5000값은 SAL의 이전 데이터이다.
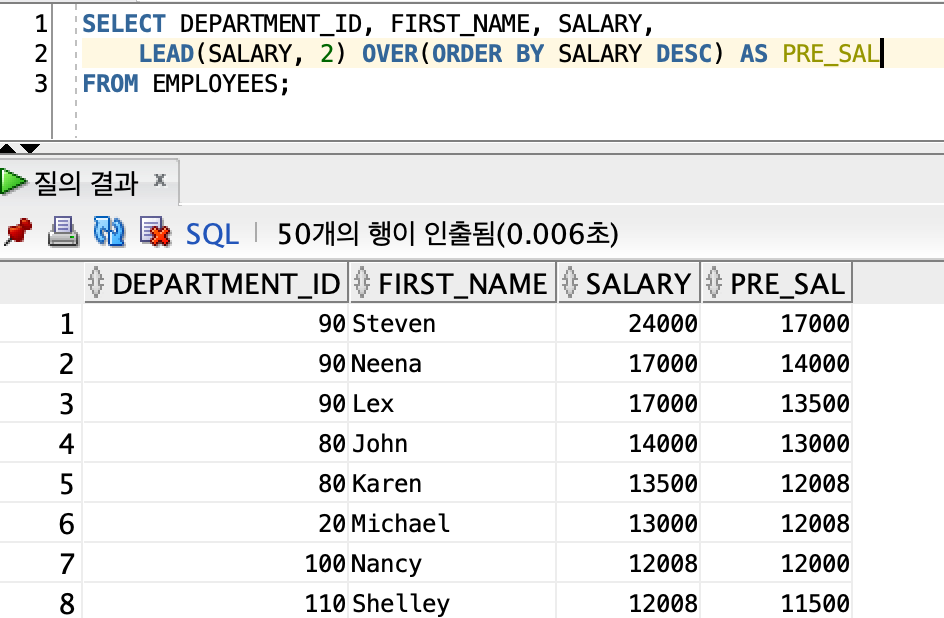
∙ LEAD 함수는 지정된 행의 값을 가지고 오는 것이다.
∙ LEAD의 기본값은 1이며, 첫 번째 행 값을 가지고 오는 것이다.
5️⃣ 비율 관련 함수
∙ 비율 관렴 함수는 누적 백분율, 순서별 백분율, 파티션을 N분으로 분할한 결과 등을 조회할 수 있다.
| 비율 함수 | 설명 |
| CUME_DIST |
- 파티션 전체 건수에서 현재 행보다 작거나 같은 건수에 대한 누적 백분율을 조회한다. - 누적 분포상에 위치를 0~1 사이의 값을 가진다. |
| PERCENT_RANK | 파티션에서 제일 먼저 나온 것을 0으로 제일 늦게 나온 것을 1로 하여 값이 아닌 행의 순서별 백분율을 조회한다. |
| NTILE | 파티션별로 전체 건수를 ARGUMENT 값으로 N 등분한 결과를 조회한다. |
| RATIO_TO_REPORT | 파티션 내에 전체 SUM(칼럼)에 대한 행 별 칼럼 값의 백분율을 소수점까지 조회한다. |
- PERCENT_RANK
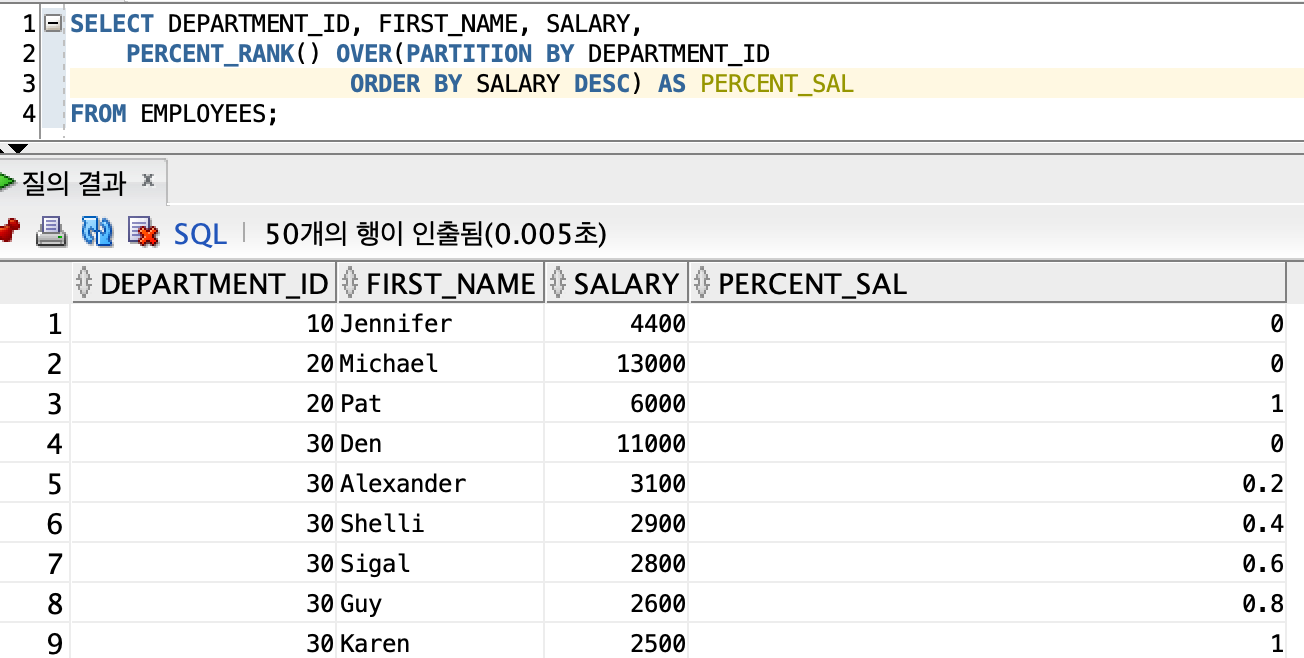
∙ PERCENT_RANK 함수는 파티션에서 등수의 퍼센트를 구한 것이다.
- NTILE
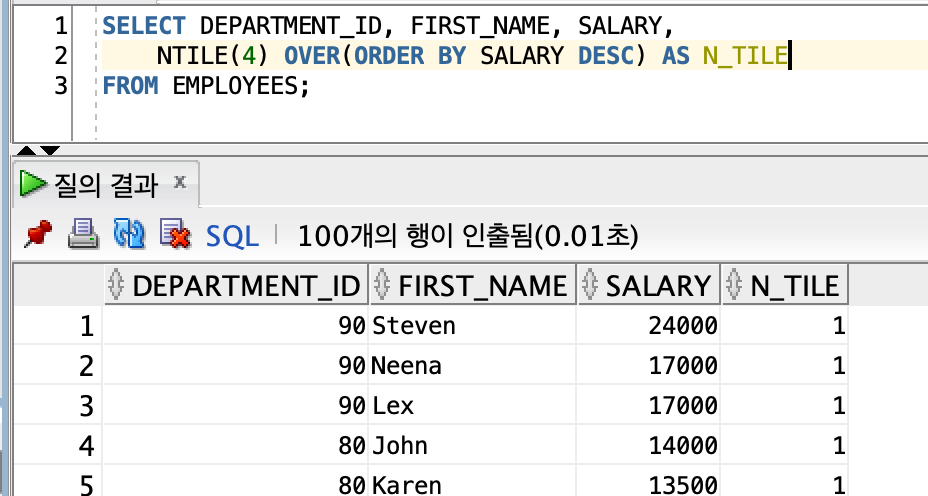
∙ NTILE(4)는 4등분으로 분할하라는 의미로 위의 예에서는 급여가 높은 순으로 1~4등분으로 분할한다.
'DB > SQLD' 카테고리의 다른 글
| [SQLD] SQL 활용 - Table Partition (0) | 2020.03.21 |
|---|---|
| [SQLD] SQL 활용 - Group Function (0) | 2020.03.12 |
| [SQLD] SQL 활용 - Subquery (0) | 2020.03.11 |
| [SQLD] SQL 활용 - Connect by(계층형 조회) (0) | 2020.03.11 |
| [SQLD] SQL 활용 - Join (0) | 2020.03.11 |


